


We’ve previously written about how we do bug fixes, feature additions & refactors. Today I want to talk about how we do large-scale, potentially high-impact refactors. What do we mean by this? Consider that when we refactor a component, we are usually
- adding, eliminating, or otherwise changing lines of code; while simultaneously
- striving to maintain the same behavior we had before.
If we need to change a lot of lines of code to implement a refactor, that’s “large-scale”. And if the behavior we are striving to maintain through our refactor is complex enough that any change in behavior is potentially a breaking change, that’s “high-impact”.
Such refactors may start to feel like re-implementations, and that’s not a bad way to frame it! By thinking about a refactor as introducing “v2” of an existing “v1” component, we can start to ask a number of helpful questions:
- How do we ensure bug-for-bug compatibility between v1 and v2?
- How do we control the rollout (and rollback) of v2?
- How do we know v2 is working?
Answering each of these questions is key to de-risking large-scale, potentially high-impact refactors, and it all boils down to testing, rollout & observability. Let’s dive in!
Testing
Before even attempting a refactor, it’s worth asking, “Do we know how our system currently behaves?” Ideally, the system’s behavior is already codified with tests, and you’ll be able to use these tests to evaluate the behavior of your refactor. But if you don’t have tests already… you need to write them, especially if the behavior you’re refactoring is complex. Otherwise, how will you know if your refactor broke something?
By testing at build time — using combinatorial and differential testing techniques — and at runtime — using shadow testing — we codify our system’s expected behavior, ensure our refactor exhibits the same behavior, and capture any discrepancies, even as the refactor runs in production. This gives us ample opportunity to catch regressions before exposing them to customers.
Combinatorial testing
Combinatorial testing can be an effective way to cover a component’s behavior in tests. The idea is simple: generate combinations of API inputs and test them. Of course, depending on the test inputs, we might have to be careful in how we generate them; however, for a simple example, consider the following:
The number of tests we generate above is equal to the cardinality of <span class="code-exp">stringInputs</span> × the cardinality of <span class="code-exp">numberInputs</span> × the cardinality of <span class="code-exp">booleanInputs</span>. If the set of inputs is small and discrete, we may actually be able to test our component exhaustively, and this gives a high degree of confidence in our component’s behavior; but, if the set of inputs is large or infinite, we’ll need to more carefully choose the test inputs we test against in order to run them in a practical amount of time. Although such tests may not be exhaustive, they can be “effectively exhaustive” and fast enough to run on every commit.
We have used this at Propel to generate thousands of tests for our components.
Differential testing
Differential testing compares the behaviors of two or more implementations of the same “thing”. That “thing” could be a function, a class, a program, an entire system, etc., but the idea is that we provide the same inputs to each implementation and compare their behaviors and outputs.
When executing large-scale, potentially high-impact refactors, we want to assert that our refactored v2 implementation behaves the same as our existing v1 implementation. So another way that we think about differential testing is using our existing v1 implementation to generate golden tests that we evaluate the refactored v2 implementation against.
Combined with combinatorial testing, this can be an effective way to assert equivalence between an original piece of code and its refactor.
Shadow testing
Shadow testing is like differential testing in production where, instead of authoring test cases ourselves, we use live customer traffic as test cases. Customer requests are received by our service, and then passed to both the existing v1 implementation of our component, as well as the refactored v2 implementation. Any differences between the two can be logged and reviewed for correctness without exposing customers to potentially breaking changes in the refactor. The strength of shadow testing is that rather than try to guess at representative API inputs to test against, we can test against the actual API inputs used in production.
Rollout
The forms of testing we discussed above give a lot of confidence in our refactor, but now we need actual customers to use it in production. The question then is how do we roll out our refactored v2 implementation to production and start accepting customer traffic? And how do we roll back if it turns out that there’s a problem?
Tired: Deployment & canaries
One option is to build a new version of our software that exclusively uses the refactored v2 implementation and ship that all the way to production. If we have the capability to run canary deployments, we might even deploy N copies of our software within a fleet of M total copies and monitor them before doing a full deployment.
Depending on how customer requests are distributed within our fleet, we can expose 1%, 10%, etc., of customer requests to our new software by tweaking N and M. By monitoring the canaries — for example, via a health check endpoint — we allow ourselves the opportunity to roll back if we see customer requests failing under the refactored v2 implementation.
Drawbacks
At Propel, we aren’t big fans of this approach. First, shipping changes by deploying software gives up a lot of control. Yes, you can target 1%, 10%, etc., of customer traffic, but you can’t segment beyond that. For example, we might want to ship a change to employee accounts first, validate, then ship to batches of customers based on access patterns, validate, and so on.
Second, deployments are relatively slow. If you have a super-fast deployment system, and if you can roll back super-quick, that’s amazing! But, in general, we’ve not found this to be the case. We prefer to be able to enable and disable features at a moment’s notice, without waiting on a deployment.
Finally, if you have to cut a whole new version of the software and wait for the change to be validated in production, you’re potentially slowing down your ability to continuously integrate and deploy your software to production. At Propel, we sometimes gradually deploy changes to customers over the course of a week. This would be untenable if shipping the changes was tied to deployment.
Wired: Feature flags
So what do we use instead? Feature flags! Feature flags give us the ability to selectively ship changes to customer accounts, to selectively ship changes to specific customers, and to do this all on the order of seconds, rather than minutes. We do this by merging changes to main behind feature flags. These changes can be deployed all the way to production, but enabled at a later time. In this way, “shipping the change” can be done independently of deployment.
We use a vendor for our feature flags, LaunchDarkly; however there are plenty of other providers you can look at, and there’s even an OpenFeature project, under the Cloud Native Computing Foundation, to standardize feature flags.
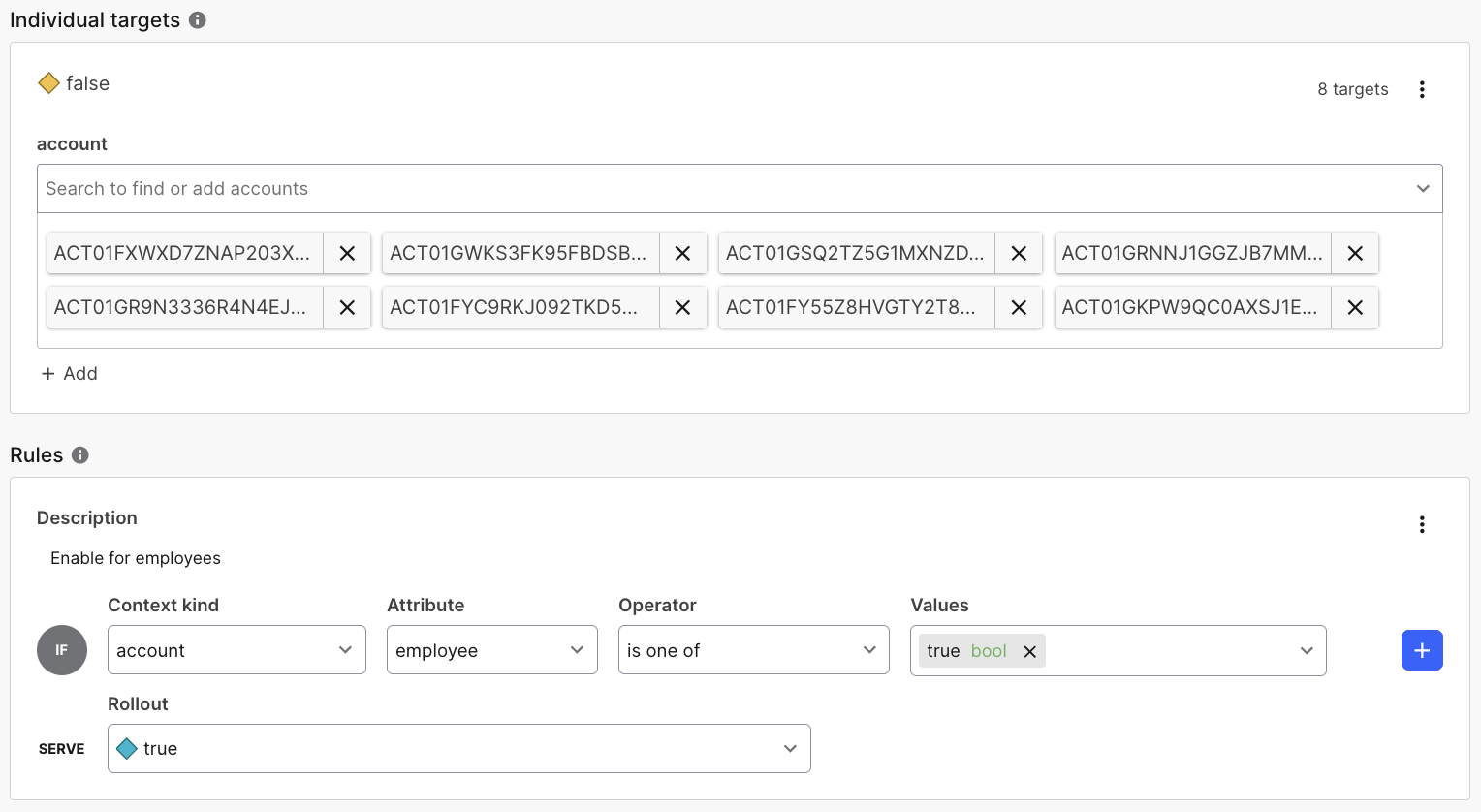
Check out the screenshot below of an actual feature flag we use in production. We are able to target specific accounts by specifying “Individual targets”, and we can target account segments by specifying “Rules”. For example, the rule below enables our feature flag for all of our employee accounts by matching on the <span class="code-exp">employee</span> attribute.
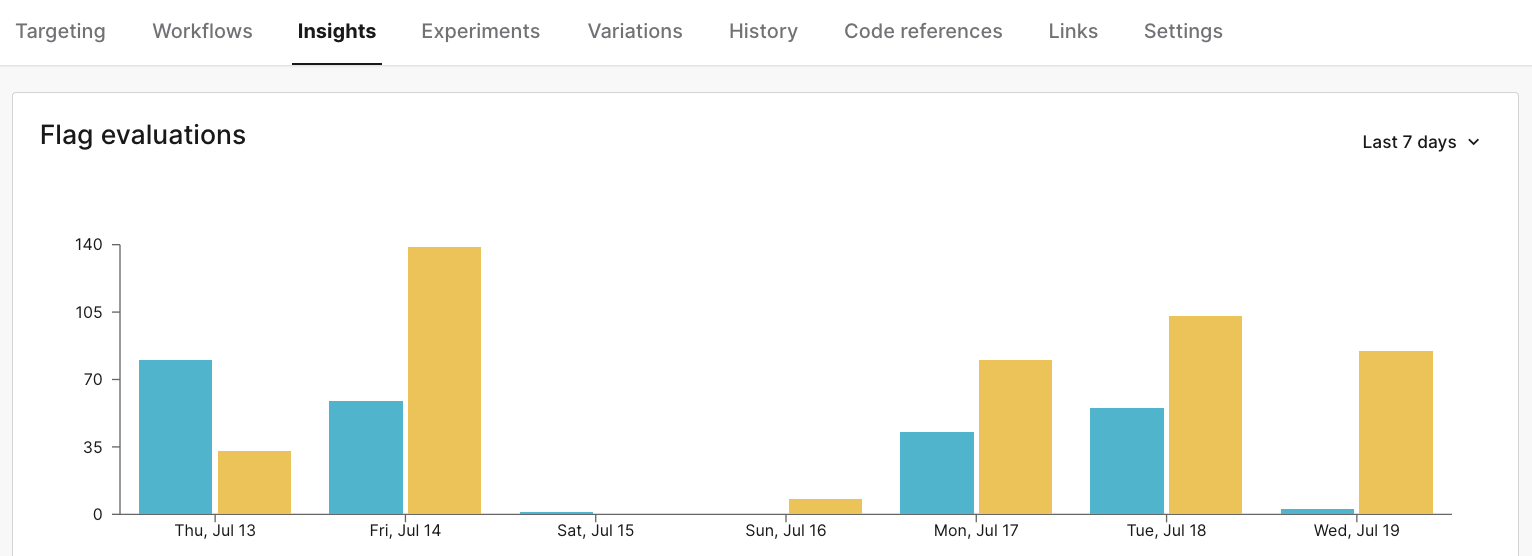
Something else we like about LaunchDarkly: it grants us insight into feature flag evaluations over time. We can very gradually roll out a change (for example, over a week) and confirm that customers are getting served the new functionality:
Observability
So imagine we’ve implemented our refactor. We did a bunch of testing upfront. We’ve gated access to the refactor behind a feature flag. We’re ready to deploy to production, and we’re ready to start rolling out the change to customers. How will we know it’s working? How do we know if we need to roll back and disable the change?
We need observability! At a minimum, we need our system to publish information about succeeding and failing customer requests. Even better, we should publish our latencies for handling customer requests. If we can get this data out of our system, we can judge whether or not our change is behaving as intended.
At Propel, we’ve instrumented our system using OpenTelemetry. OpenTelemetry is another Cloud Native Computing Foundation project to standardize tracing, telemetry, and, in general, observability. By using their libraries and instrumentations, we can collect traces for every customer request we handle.
We send these traces to Honeycomb, and Honeycomb allows us to build SLOs and triggers that will alert us to issues in production. If a change in production introduces latency or increases our error rate, this triggers an incident and alerts our on-call engineer to roll back.
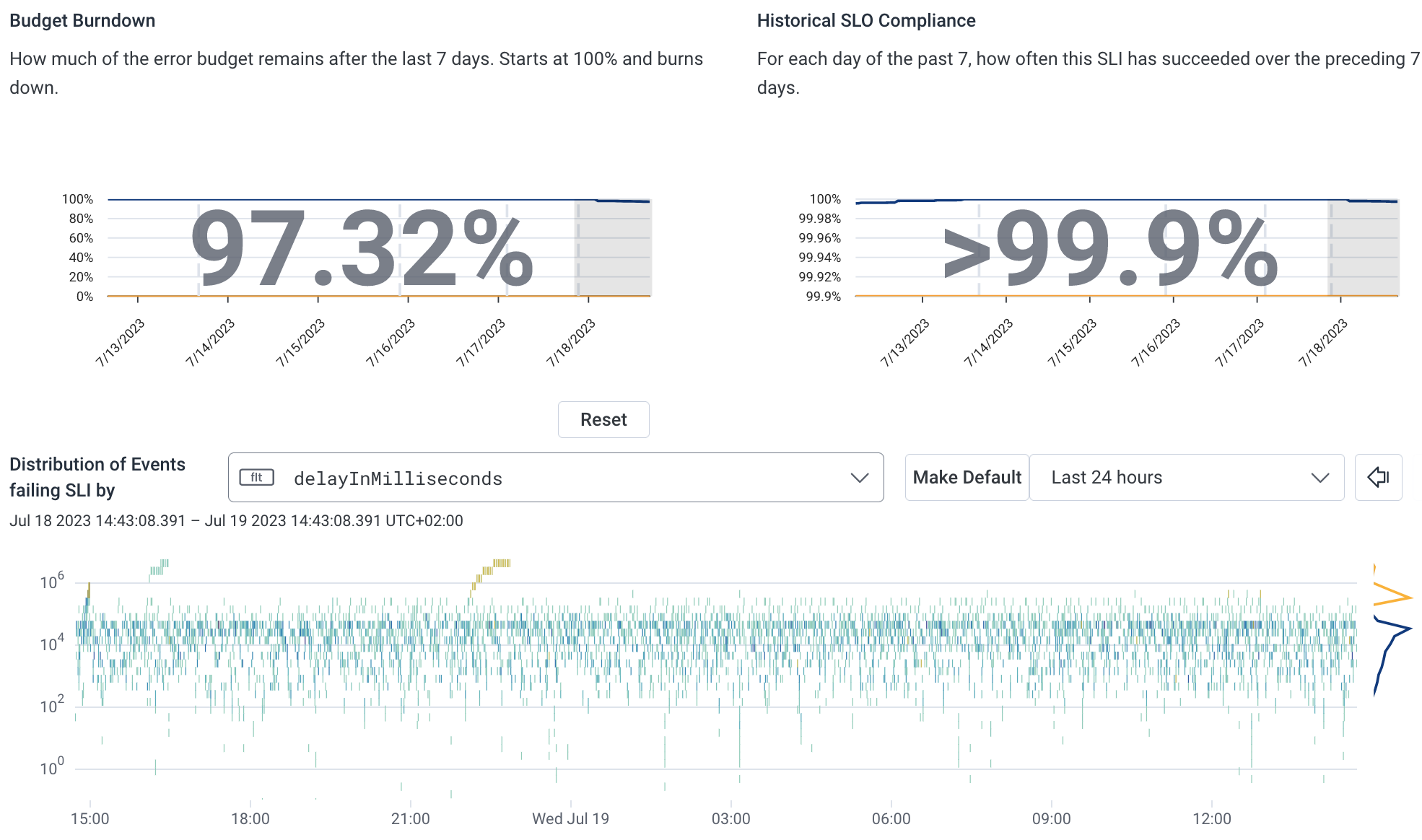
Conclusion
By testing up front, by controlling rollout using feature flags, and by enabling observability in our production environments, we’ve been able to de-risk shipping large-scale, potentially high-impact refactors to our system. And doing so protects the customer experience.
These techniques are of course not limited to refactors: any potential high-impact change or feature addition can be developed and rolled out to customers this way. We hope you can benefit from what we’ve learned and apply it in your own engineering practice.
If you like what you’ve read, or you’re interested in learning more about Propel, reach out to hello@propeldata.com. Or have a listen to the Data Chaos podcast, where we deep dive into the entropy that exists in the world of data. 👋

