


When to use a Snowflake API
You may want to use an API on top of your Snowflake data in a few different situations.
- [In-product analytics] You have internal analytics data and you want your users to be able to view it
- [Usage metering] You want to keep track of usage data and use that for billing or other purposes
- [Using Snowflake as your application database] You want to use data in your Snowflake to power all or part of your customer-facing application
Let’s quickly dive into each of these use cases for further clarification.
1. [In-product analytics] You have internal analytics data and you want your users to be able to view it
Perhaps you’re managing a SaaS product. Or maybe a consumer app with millions of users.
Whatever it may be, having a world-class in-product analytics experience will help your product stand out from your competitors.
For example, you may want to let your users visualize their usage data.
Or perhaps you want to help your users notice new patterns in their sales data by visualizing it.
In each of these use cases, using an API on top of your Snowflake data, you can empower your users to be able to access data they need to make better decisions when using your product.
2. [Usage metering] You want to keep track of usage data and use that for billing or other purposes
Suppose you’re managing a product that uses an LLM API such as a ChatGPT API, or your company uses any other resource that costs you money every time you use it.
Then, you may want to charge customers based on their monthly usage.
If this data is already in Snowflake, you may want to use an API to access it for billing and usage-metering purposes.
3. [Using Snowflake as your application database] You want to use data in your Snowflake to power all or part of your customer-facing application
Suppose your users request features that require you to use some of the data that’s available in Snowflake.
Then, you’ll need a way to quickly and securely access the relevant user data in Snowflake from your product.
In such a case, being able to use a fast API on top of your Snowflake data may be crucial for achieving optimal product experiences.
How to use an API on top of Snowflake
Now that we’ve covered a few use cases where using an API on Snowflake may be useful, let’s go over a few different ways of implementing it.
- Snowflake’s REST API
- Snowflake’s language-specific connectors
- An analytics platform that includes a semantic layer, such as Propel
Examples
To explain how a Snowflake API works in these three methods, we will use the following example throughout this post. If you prefer to get an overview of the three methods without following along, feel free to skip to the next section.
Example data setup
Suppose that you’re running a SaaS application that manages sales of taco restaurants.
Then, you may have data that looks like this:
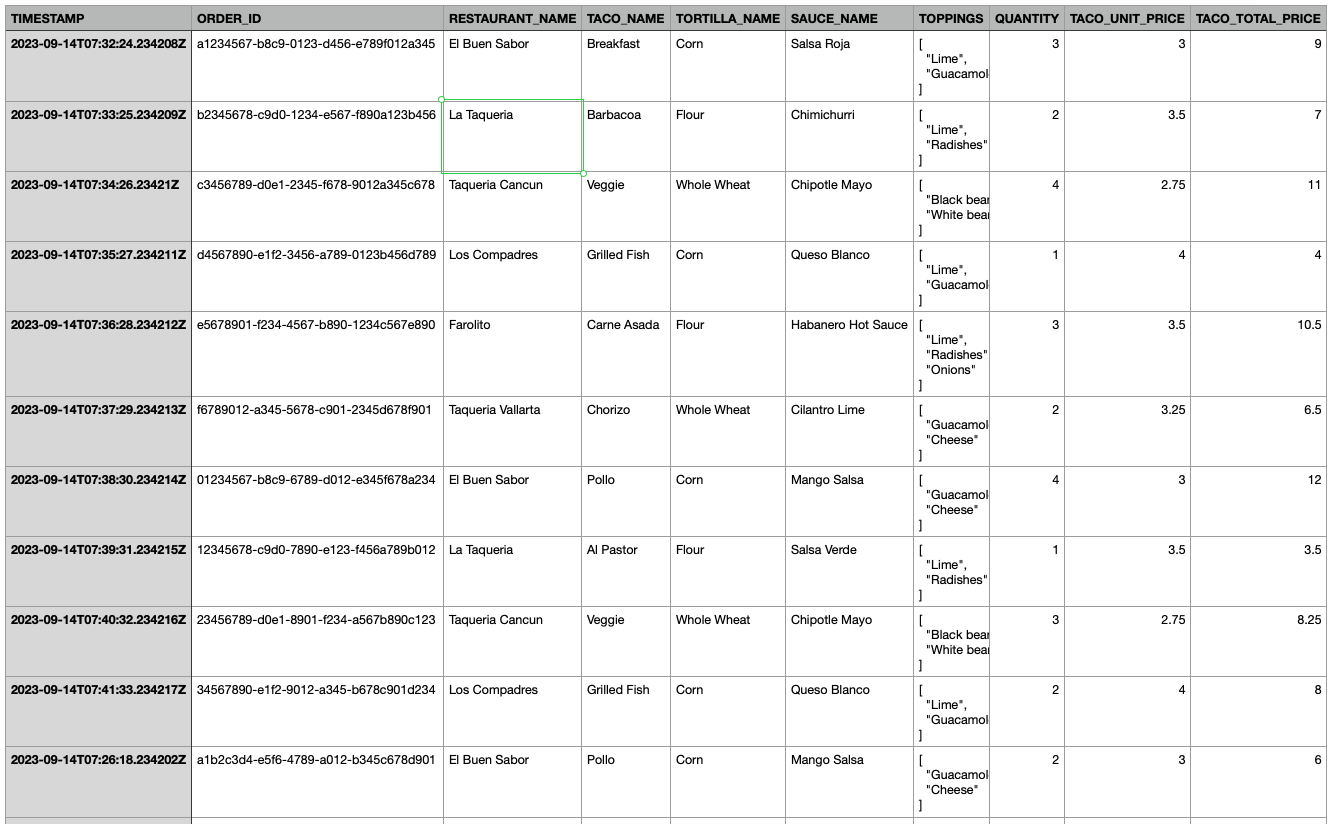
As you can see, this data represents taco orders from various restaurants. Each row captures a unique order with details such as:
- TIMESTAMP: The exact date and time the order was placed.
- RESTAURANT_NAME: The name of the restaurant where the taco was ordered.
- TACO_NAME: The type of taco ordered, like Carne Asada or Veggie.
- TOPPINGS: A list of additional toppings added to the taco, like Guacamole or Radishes.
- TACO_TOTAL_PRICE: The total price for the tacos of this type.
You can create data like this in your Snowflake account with two queries.
First, create a table by running this query:
Then, insert 20 rows that fit this format with this query:
By running the following query:
You should be able to verify that you’ve successfully created this data:
.png)
Now, let’s dive into each of the three methods we mentioned earlier.
1. Snowflake’s REST API
Snowflake has its own REST API that allows you to execute queries and monitor the progress of those executions.
Below, we’ll go over a step-by-step introduction of how to get started and use Snowflake’s REST API, as well as a few examples.
However, let’s first cover the pros and cons of this approach:
Pros
- It lets you execute any SQL query that’s available in Snowflake.
- It is natively supported by Snowflake.
Cons
- If you need to use this endpoint many times, for example when you need to serve data for many users, then this can get expensive fairly quickly.
- Supporting high concurrency can be expensive as well.
- It may not have the best query time particularly when dealing with complex queries.
- When serving user data, you need to set up the logic to filter the data so users only have access to their own data.
- Setting up authentication can be cumbersome as we’ll see below.
If your particular use case involves high concurrency and demands low latency, then an alternative solution is probably a better fit for you, as you’ll see later in this post.
1-A. Authentication
To get started with Snowflake’s REST API, you need to authenticate your requests to ensure secure access to your data.
To do this, there are two methods:
- Key pair authentication
- OAuth
Here, we’re going to cover key pair authentication.
To learn more about OAuth authentication with Snowflake, refer to the Snowflake documentation on OAuth.
Key pair authentication: a brief overview
Key pair authentication is a method used by Snowflake's REST API to verify your identity. It involves two main components:
- Public key: Shared with Snowflake and stored in your account.
- Private key: Kept secret by you and used to generate authentication tokens.
The process is as follows:
- You generate a unique pair of public and private keys.
- The public key is assigned to your Snowflake account.
- For authentication, you create a token using your private key.
- Snowflake validates the token using the associated public key, confirming your identity.
This method ensures secure access, as only the holder of the private key can generate a valid token for their account.
Setting up key pair authentication
1. Generating the Key Pair
To generate a public-private key pair, you can use tools like OpenSSL. Here's a basic command to generate an RSA key pair:
This will create a private key (rsa_key.p8) and a public key (rsa_key.pub).
2. Assigning the Public Key to your Snowflake user
To assign the public key to your Snowflake user, you can use the <span class="code-exp">ALTER USER</span> command:
Replace <span class="code-exp-bracket">your_username</span> with your Snowflake username and <span class="code-exp-bracket">contents_of_rsa_key.pub</span> with the actual content of your public key file, excluding the delimiters (i.e., <span class="code-exp">-----BEGIN PUBLIC KEY-----</span> and <span class="code-exp">-----END PUBLIC KEY-----</span>).
After setting the public key, you can verify its assignment by running the <span class="code-exp">DESCRIBE USER</span> command:
The output should show the <span class="code-exp">RSA_PUBLIC_KEY_FP</span> property, indicating that the public key has been successfully assigned to the user.
Note:
- Only security administrators (i.e., users with the <span class="code-exp">SECURITYADMIN</span>role) or higher can alter a user.
3. Verifying the Connection with SnowSQL
To verify that the key pair is working as expected, you can use SnowSQL to connect to your Snowflake account:
You can find your Snowflake account identifier as part of the URL you use to log in to Snowflake. The format is generally <span class="code-exp-bracket">account_identifier.snowflakecomputing.com</span>.
If your private key is encrypted, SnowSQL will prompt you for the passphrase you set during key generation.
Running this command should successfully connect you to your Snowflake account if the key pair is correctly set up.
4. Generate Fingerprint and Create JWT in Python
After verifying the connection, you can obtain the fingerprint of your public key by running the <span class="code-exp">DESCRIBE USER</span> command in Snowflake. Look for the <span class="code-exp">RSA_PUBLIC_KEY_FP</span> property in the output.
Then, install the required Python package:
Now, you can generate a JWT in Python using the following example:
Replace <span class="code-exp-bracket">account_identifier</span> and <span class="code-exp-bracket">user_name</span> with your Snowflake account identifier and username, respectively. Replace <span class="code-exp-bracket">RSA_PUBLIC_KEY_FP</span> with the fingerprint obtained from <span class="code-exp">DESCRIBE USER <span class="ce">your_username</span>;</span>.
For Java and Node.js examples, please refer to the official Snowflake documentation.
5. Verifying Key Pair Authentication with a cURL Request
To verify that your key pair authentication is set up correctly, you can make a test API request using curl. Here's how to execute a simple SQL query:
Replace <span class="code-exp-bracket">your_generated_jwt_token</span> with the JWT token you generated and <span class="code-exp-bracket">account_identifier</span> with your Snowflake account identifier.
Run this <span class="code-exp">curl</span> command in your terminal. If everything is set up correctly, you should receive a JSON response from Snowflake containing the results of the SQL query.
Interpreting a Successful Response
A successful response will look like:
Key Points:
- HTTP 200 OK: Request was successful.
- <span class="code-exp">data</span>: [["7.33.1"]]: Current version of Snowflake, enclosed in a nested array.
- <span class="code-exp">message</span>: "Statement executed successfully.": Confirms successful execution.
- <span class="code-exp">resultSetMetaData</span>: {...}: Metadata related to the response, indicating additional information is available.
This verifies that your key pair authentication is set up correctly and functional.
1-B. Making API Requests with Snowflake's REST API
After successfully setting up authentication, you can start making API requests for various operations like querying, inserting, and updating data. All these operations use the <span class="code-exp">/api/v2/statements</span> endpoint.
Querying Data
Here's an example using <span class="code-exp">curl</span> to fetch the first 5 rows from the <span class="code-exp">taco_orders</span> table:
Replace <span class="code-exp-bracket">your_generated_jwt_token</span> and <span class="code-exp-bracket">account_identifier</span> with your JWT token and Snowflake account identifier, respectively.
When executed successfully, you should expect an output similar to the following:
Other operations
For inserting or updating data, you can use the same endpoint. Simply change the SQL statement in the request payload. For example, to insert a new row into <span class="code-exp">taco_orders</span>, you would change the <span class="code-exp">"statement"</span> value to an appropriate <span class="code-exp">INSERT INTO</span> SQL command:
By following this approach, you can perform a variety of data operations using Snowflake's REST API.
For more details on using Snowflake's SQL API, you can refer to the official Snowflake documentation.
2. Snowflake’s language-specific connectors
Snowflake offers SDKs and connectors for various programming languages such as Python, Java, .NET, and more. The full list of available languages for connectors and drivers can be found in the Snowflake documentation.
Pros
- Ease of use: If you're already using one of the languages for which a connector or driver is available, integrating Snowflake into your existing stack becomes straightforward.
Cons
- Language dependency: You're tied to the programming language for which you've set up the connector.
- Code maintenance: As your queries get more complex, you may need to manage a larger codebase.
Let’s take a look at how this works with Python as an example.
Installation and establishing a connection (Python example)
First, install the Snowflake Python connector package:
Then, establish a connection to Snowflake and execute a query:
You should see an output like this:
Using cursors to navigate query results
Cursors are not just for executing queries; they also keep track of which records you've accessed so far. This is particularly useful when you're working with large datasets and you want to process records in chunks. Here's an example that demonstrates this:
In this example, we first fetch and print the first 5 rows using <span class="code-exp">fetchone()</span>. The cursor keeps track of this, so when we fetch the next 5 rows, it continues from where it left off.
This way, you can navigate through your query results in a controlled manner, making cursors a useful tool for data retrieval.
Note on Snowpark
For more advanced data engineering tasks, Snowflake also offers Snowpark, a service designed for more native and idiomatic data transformation and analysis. For more information, check out Snowpark's official page.
3. An analytics platform that includes a semantic layer, such as Propel
In the previous sections, we’ve covered first-party methods to query data from Snowflake.
In this section, we’re going to cover the other option of using an analytics platform that includes a semantic layer such as Propel.
With Propel, you can create a blazingly fast GraphQL API on top of your Snowflake data. Let’s take a look at the pros and cons of this approach:
Pros
- Low latency: when compared to querying data directly from Snowflake, having a separate caching & storage system makes it much faster to query analytics data, typically in milliseconds.
- High concurrency: the serverless nature of this solution allows you to scale your service to a virtually unlimited number of concurrent users/requests.
- Better timezone handling: if you have users in different timezones, you may want to query and serve the data in their specific timezones. Propel allows you to handle this with ease.
- Better organization of your code: you won’t have to deal with dozens of individual SQL queries, and multi-tenant use cases can be handled with ease.
Cons
- Not all Snowflake SQL queries are supported yet.
This is a great option especially if you’re dealing with a situation where low latency and high concurrency is important in your use case - for example when building a customer-facing analytics dashboard.
Let’s take a look at how to set this up with the example data we saw above.
Confirm that you have the example data
Once you set up the example data following the steps explained earlier in the article, you can try running
in the correct database and schema to ensure that our example data has been correctly created.
.png)
Enable CHANGE_TRACKING
Before you attempt to set up Propel on top of this data, it’s important to enable CHANGE_TRACKING on your table with the following query:
Step 1: Sign up for Propel
Once you’ve confirmed that you have the example data (or any other data you want to use for this), you can go to propeldata.com and sign up for your Propel account there.
.png)
Step 2: Create the Snowflake user, role and warehouse for Propel
Once you sign up and sign in to Propel, we recommend that you create a dedicated Snowflake user, role, and warehouse for Propel. By creating a dedicated role and user, you can apply the principle of least privilege to give it only the privileges it needs. Additionally, by having a dedicated warehouse, you can monitor and control costs, as well as ensure you have the necessary compute to operate the integration.
Copy the script below to a new Snowflake worksheet and select the "All Queries" checkbox.
Note 1
Make sure you replace the values for the <span class="code-exp">user_password</span>, <span class="code-exp">database_name</span>, and <span class="code-exp">schema_name</span> variables with the following values before running the script.
- <span class="code-exp">user_password</span> it must be at least 8 characters long, contain at least 1 digit, 1 uppercase letter and 1 lowercase letter
- <span class="code-exp">database_name</span> with the name of the Snowflake database where your schema is located, for example <span class="code-exp">ANALYTICS</span>.
- <span class="code-exp">schema_name</span> with the database and schema name where your tables are located, for example <span class="code-exp">ANALYTICS.PUBLIC</span>.
Note 2
You will need to run this script with a user that has SECURITYADMIN and ACCOUNTADMIN system-defined roles.
Step 3: (Optional) Configure Snowflake Network Policy
If you have defined a Snowflake Network Policy, you need to update it to include the Propel IP address by following the instructions on modifying network policies.
Propel IP Addresses:
Step 4: Create a Data Pool in the Propel Console
Now that you have created the Snowflake user, role, and warehouse, you can create a Data Pool (Propel’s propriety storage system for fast analytical queries) in the Propel Console.
First, on the left hand side menu, click on Data Pools. Then click on the plus sign (+) to create a new Data Pool.
.png)
Click Snowflake in the next screen to select it as a data source.
.png)
Click Add new credentials:
.png)
Then enter a unique credentials name, as well as account, database, schema, warehouse, and role, user, and password.
.png)
Note:
Your Snowflake account should be in the following format "accountId.region.cloud", for example: "fn25463.us-east-2.aws". Do not include the snowflakecomputing.com domain.
When you’ve added all of those details, click Create and test Credentials.
Then you should see a “Connected” status message:
.png)
Continue with the setup flow, and then select the table as well as the columns you want to use.
You can use go with default (all columns selected):
.png)
Then select Primary timestamp to be TIMESTAMP and Unique ID to be ORDER_ID.
.png)
Click Next and make sure it’s set up correctly.
.png)
Then you can click Preview Data to make sure your data is loaded correctly.
.png)
Step 5: Create Metrics
Finally, we’ll need to create Metrics for you to be able to set up a GraphQL you can use to query your data.
On the left hand side, click Metrics and then click Create New Metric.
.png)
Then fill out the required information like so:
.png)
As you can see, here, we’re giving it:
- A unique name (Taco Soft Revenue)
- A description (Metric to keep track of taco revenue)
- Data Pool (Taco Test - or whatever name you chose earlier)
- Metric type (SUM)
- Measure (TACO_TOTAL_PRICE)
This Metric is designed to keep track of taco revenue.
Then select the columns you want to use as dimensions, which you can use to filter the Metric data.
.png)
Click Create, and you’re almost ready to start testing your GraphQL API!
Step 6: Test using the GraphQL API on top of your Snowflake data
Once you set up the Metric, click Playground. There, you can test using a GraphQL API that’s automatically set up on top of your Metric.
For example, you can click Leaderboard and create a leaderboard-like visualization with a single API call to determine, say, top-performing restaurants and their revenue.
You can see the associated query on the right-hand side.
.png)
You can learn more about how to use this GraphQL API, as well as check examples in a few different languages on the Query your data page on our documentation.
Conclusion
In this post, we’ve covered three distinct methods for creating a Snowflake API on top of your own data:
- Snowflake's REST API
- Snowflake’s language-specific connectors
- An analytic platform like Propel
Snowflake's REST API is natively supported but can be expensive for high concurrency, has complex authentication setup, and may not offer the best query times. Language-specific connectors are easy to integrate but tie you to a specific language and can complicate code maintenance. Propel excels in low latency and high concurrency, offers better timezone handling, and simplifies multi-tenant application development, making it particularly suited for customer-facing analytics.
We recommend choosing the method that best aligns with your project's specific needs.
Any feedback?
If you have any feedback on this post or on Propel in general, please feel free to let us know at yksu@propeldata.com.


